Agenda
What do we want?
Hardware & OS
Database
Middleware
API & Frontend
What do we get?
Q & A
What do we want?

What do we want?
-
high availability – our product should always be available
-
scalability – scale the service according to demands
-
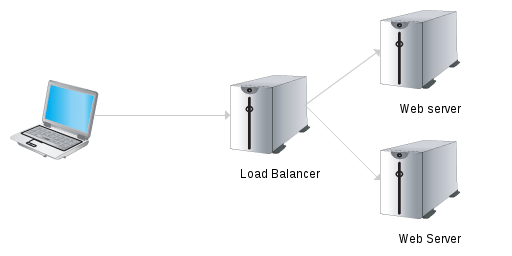
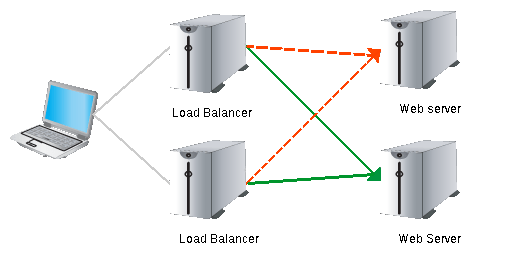
load balance – distribute the load, even between continents
-
rolling update – roll out upgrades frequently, start it on a low-load server
-
cheap – all of course very cheap... :)
What do we want?
- High availability and reliability
- Automatic failover
- Automatic load balance
- Single-Point-of-Failure
- We want to sleep well... :)
Hardware & OS – VPS
- We use virtual private servers (VPS)
- A VPS runs its own copy of an operating system
- We have superuser-level access to that operating system instance
- They are functionally equivalent to a dedicated physical server
Hardware & OS – Five data centers
- DC01 – Montreal, Quebec, Canada
- DC02 – Miami, Florida, USA
- DC03 – Nürnberg, Germany
- DCB1 – London, UK
- DCB2 – Munich, Germany
Hardware & OS – Why five data centers?
- Users from worldwide
- Reliability & availability
- Network lag between continents
- Ability of rolling updates
- Data replication
Hardware & OS – Six servers per datacenter
- Four Cassandra database nodes
- Two WildFly middleware nodes...
- ...with two Apache HTTP servers
Hardware & OS – Unified server configuration
- 2 vCPU
- 4 GB RAM
- 40 GB SSD
- 20 TB traffic
- Extendable storage volume
Hardware & OS – Monitoring and management
- DevOps aspect
- Automated everything
- Simple OS and HW metrics
- Test system-wide functions
- Gain metrics from outside
- Use the system as a user
Monitoring and management – DevOps aspect
Monitoring and management – Automate everything
- Every day: regularly restart everything
- Every week: regularly reinstall some nodes
- Every month: regularly upgrade one component
- Are you afraid? Do it often... :)
- Do it often? Automate it... :)
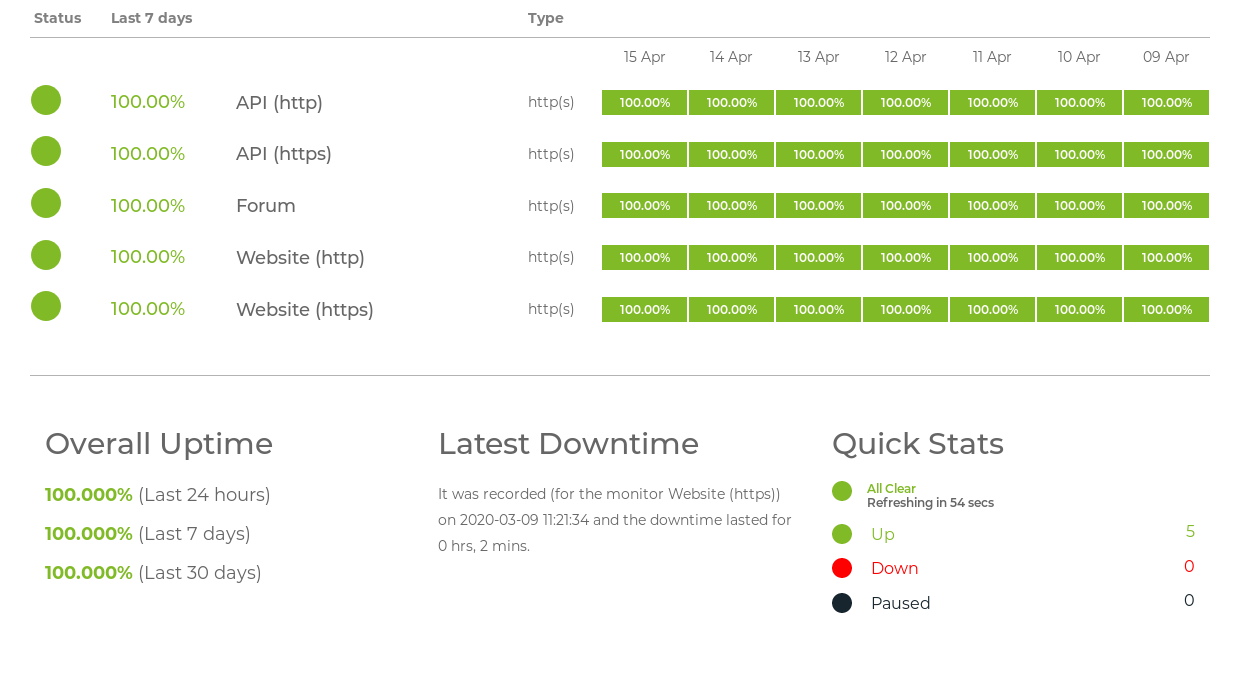
Monitoring and management – Simple OS and HW metrics
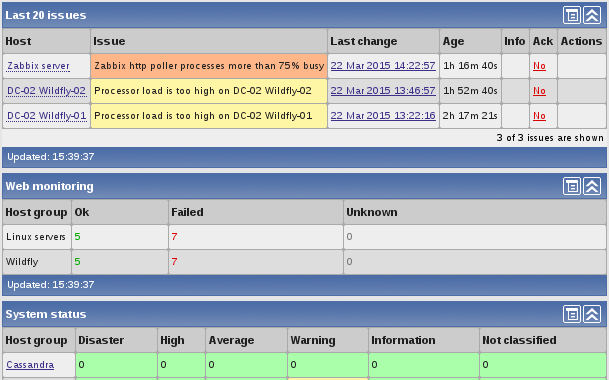
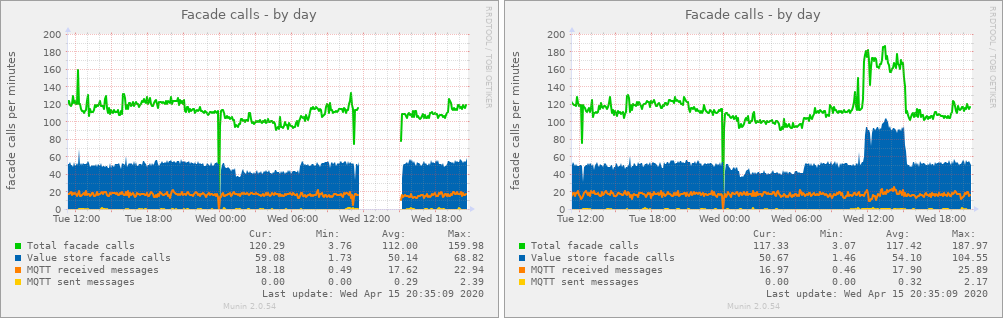
Monitoring and management – Test system-wide functions
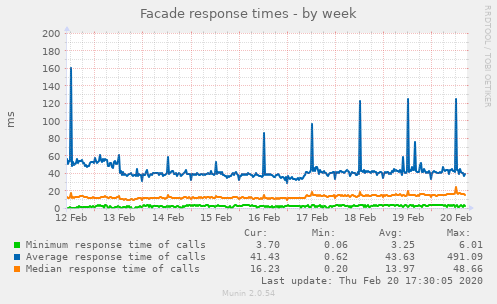
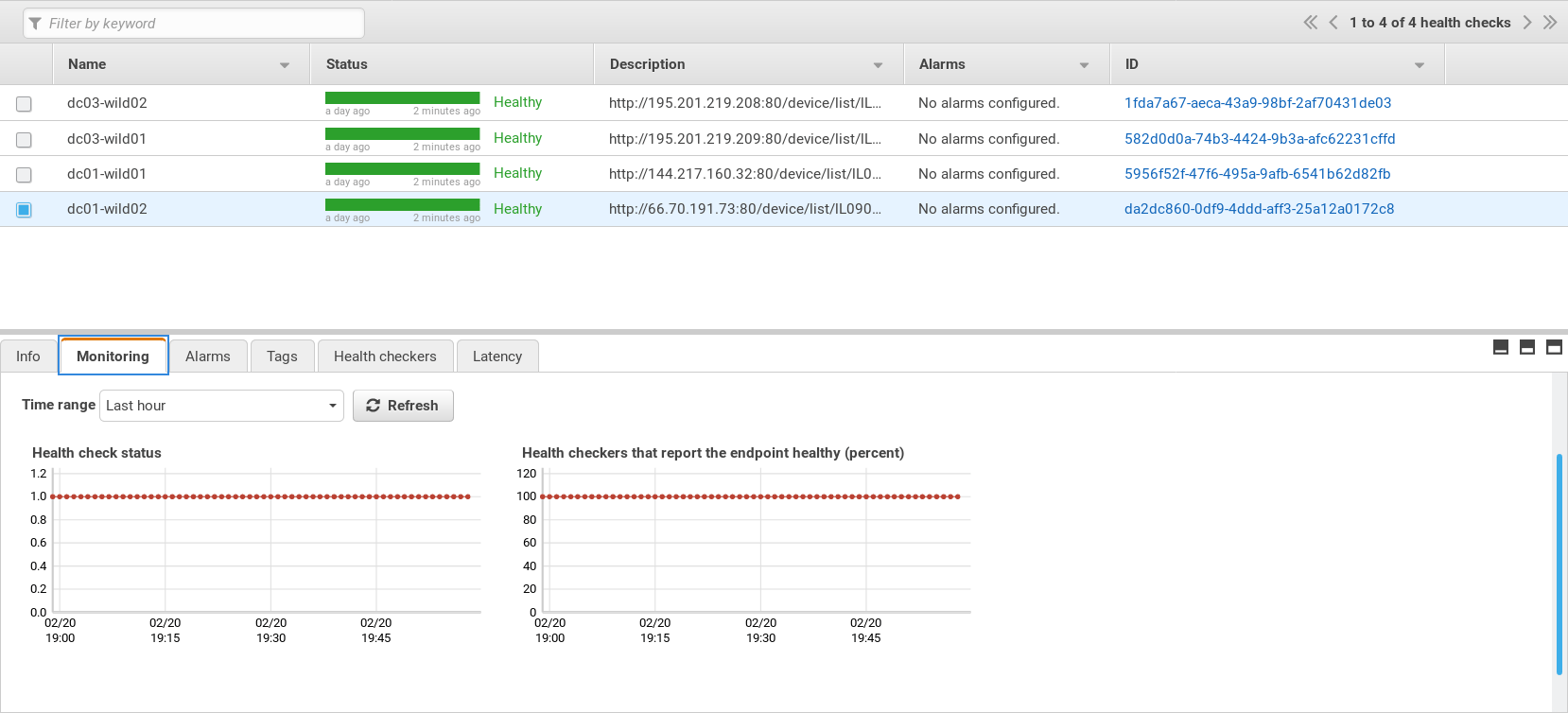
Monitoring and management – Gain metrics from outside
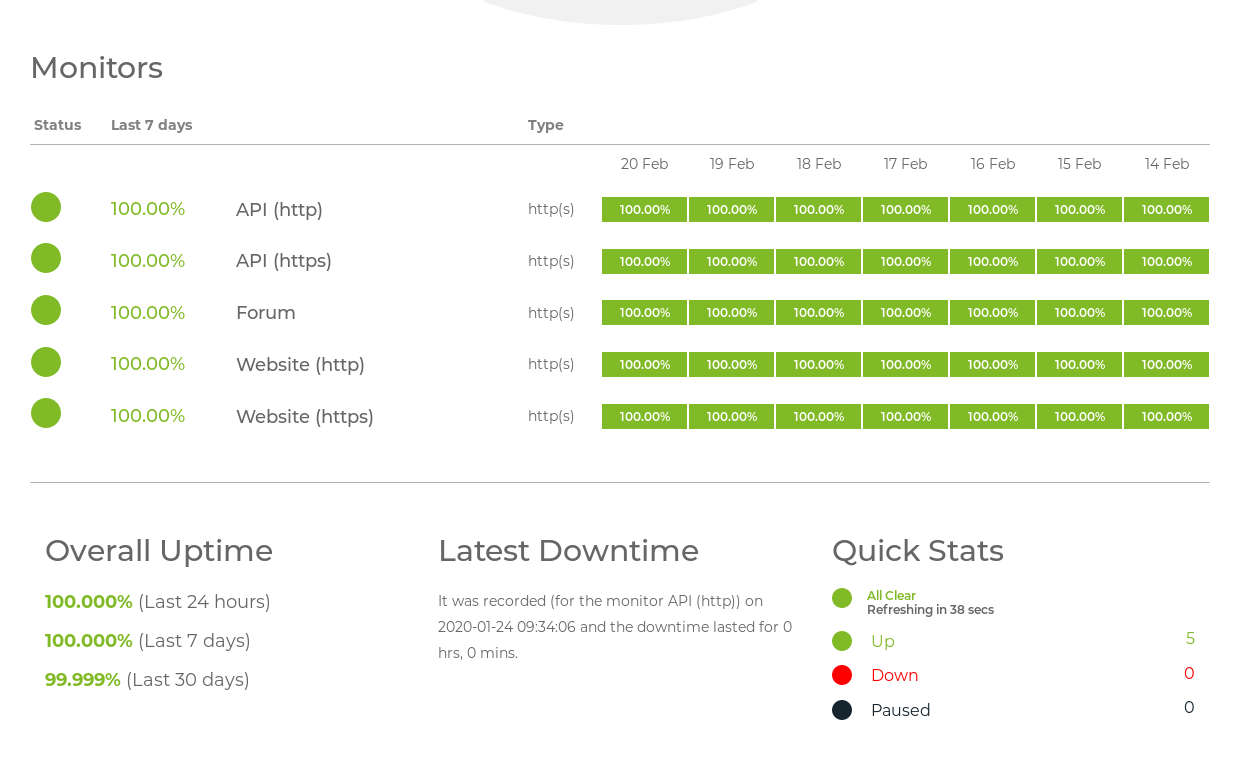
Monitoring and management – Use the system as a user
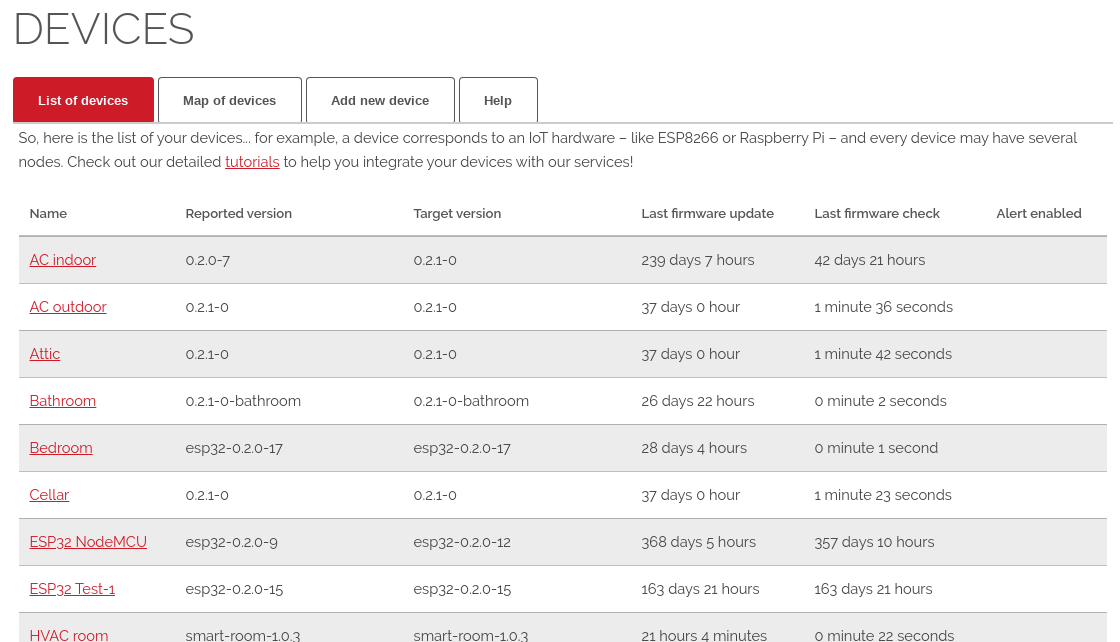
Database
http://www.datastax.com/.../apache-cassandra
It’s architected from the ground up for real-time enterprise databases that require vast
scalability, high-velocity performance, flexible schema design and continuous availability.
Database – Cassandra
- Scalable distributed database
- Elastic scalability
- Always on architecture
- Fast linear-scale performance
- Flexible data storage
- Easy data distribution
- Operational simplicity
- AID transaction support
Database – Cassandra
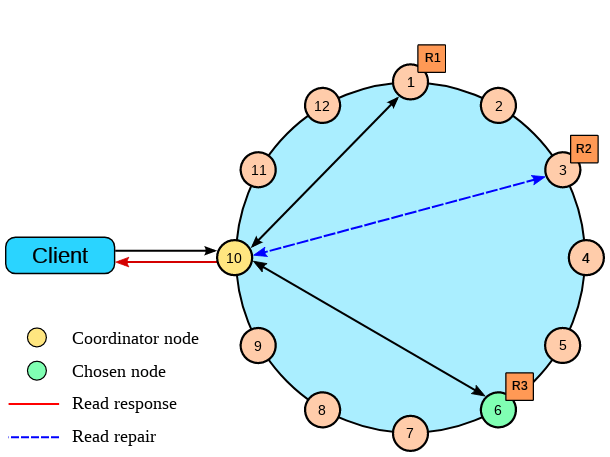
- Contains no single point of failure
- Replicating data across multiple datacenters
- Administration duties are greatly simplified
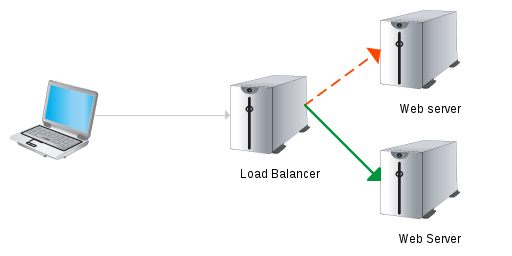
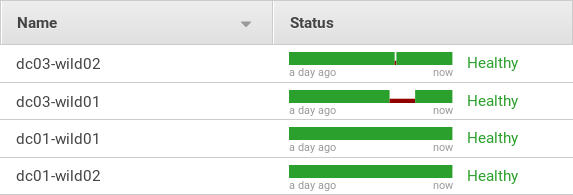
Database – Cassandra failover
Database – Cassandra load capacity
Most workloads work best with a capacity under 500GB to 1TB per node depending on I/O. Maximum
recommended capacity for Cassandra 1.2 and later is 3 to 5TB per node for uncompressed data.
WARN Only 20.140GiB free across all data volumes. \
Consider adding more capacity to your cluster
Database – Cassandra tools
Datacenter: DC03
================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns Host ID Rack
UN xxx.xxx.xxx.121 5.2 GiB 32 ? 70cbbbc4-2f52-4321-8d75-9591d175da5f RACK01
UN xxx.xxx.xxx.120 4.77 GiB 32 ? 20cd5c53-17bd-4229-90b4-e8334334c0fa RACK01
UN xxx.xxx.xxx.122 5.26 GiB 32 ? 6c13cda3-f752-4c5e-8e6e-f4aa8ff24b5c RACK01
UN xxx.xxx.xxx.119 5.2 GiB 32 ? 75b510b2-b891-4e31-b210-aaef3c0c229b RACK01
Middleware – Wildfly
https://wildfly.org/
WildFly is a flexible, lightweight, managed
application runtime that helps you build amazing
applications.
Middleware – Wildfly
- Full featured Java EE 8 container.
- Unparalleled Speed
- Exceptionally Lightweight
- Powerful Administration
- Supports Latest Standards and Technology
- Modular Java
Middleware – Wildfly
- World wide cluster:
- dc01-server-group
- dc02-server-group
- dc03-server-group
- WebSocket and REST interfaces
- Mostly stateless components
Middleware – Wildfly
- TCP ping based cluster
- TLS/SSL based node security
- Public IPs behind firewall
Middleware – Wildfly
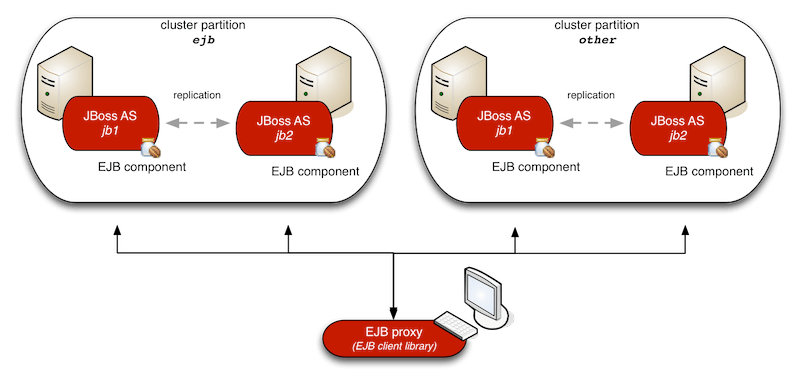
- Stateful clustered components
- Clustered and transacted queue support
- Clustered scheduler jobs
- Container managed executors
Middleware – Failover
Middleware – EMQX
https://www.emqx.io/
EMQ X is a highly scalable, real-time distributed MQTT message broker
for large-scale IoT applications in 5G era. A single node broker can sustain
one million concurrent connections… and an EMQ X cluster – which contains
multiple nodes – can handle tens of millions of connections.
Middleware – EMQX
- Basically an MQTT broker
- Rule engine
- Fine grained ACL
- Rate limits and quotas
Middleware – EMQX
- CoAP, MQTT-SN, Stomp, ..., buzzwords
- Store engine (Cassandra supported!)
- Message bridges
- 3rd party plugins
How much does it cost?
Cost of each DC:
- 4 x Cassandra ~ 20 EUR / month
- 2 x Wildfly ~ 10 EUR / month
- ~ 30 EUR (~ 10,000 HUF) / month
How much does it cost?
- 3 live DC ~ 90 EUR / month
- 2 backup DC ~ 30 EUR / month
- Amazon Route 53 ~ 5 EUR / month
- ~ 125 EUR (~ 45,000 HUF) / month
What do we get?
- Robust and high availability system
- Fault tolerant mostly auto-healing
- Geolocation based routing
- 11 replica of each data
- 2500 - 3000 req/sec load capacity
Technology stack
- CentOS 8 (and CentOS 7)
- Puppet 6.x
- JDK 11 (and JDK 8)
- Cassandra 3.11.x
- WildFly 18.0.1
- EMQX 4.0.x
- Android 5.0+
- IoT devices
 IoT GURU Cloud
IoT GURU Cloud